Customer Analysis Part II: Classification
This is part two of a multi-part series. Part one, segmentation and clustering, can be found here.
Code for this section can be found in the repo: https://github.com/jamesdeluk/data-science/blob/main/Projects/customer-analysis/ca2-classification.ipynb
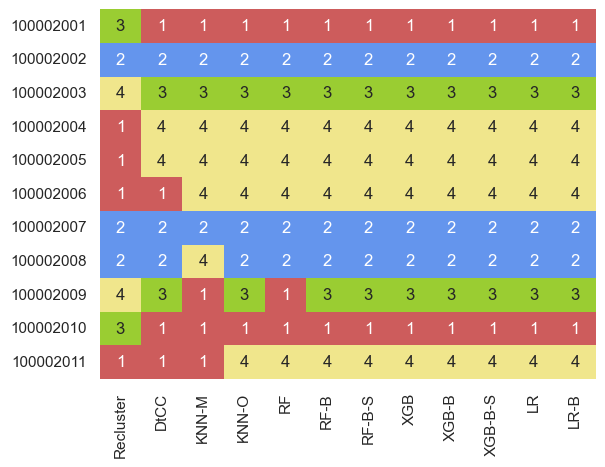
Intro Great, we have our customers clustered! But, hopefully, over time, we’ll gain more customers, and they’ll need to be assigned to an existing cluster. This is called classification. There are a few techniques for doing this.
First, let’s remind ourselves what our current clusters look like by grouping the data and finding the means, as we did in part one: