
Thursday, January 2, 2025 | 11 minutes
Podcast sentiment and topic analysis
Intro
I am a bit of a podcast addict. One of the podcasts I listen to most, The Jordan Harbinger Show, has Feedback Friday every week. It’s effectively an agony aunt, except with two uncles. I always loved it, but over time I’ve felt it has become too negative - too many stories about addiction and abusive relationships. They’re interesting to discuss, but they’re a bit depressing.
I wanted to test this hypothesis. Jordan is nice enough to provide all the transcripts on his website, so I thought I’d analyse the FBF episodes from the last year and see if they really are negative. While I had the data, I thought it would be interesting to extract common themes and topics too.
I saved all the transcripts to a transcripts folder, as [episode_number].txt. The repo contains 1000.txt as an example - and, of course, the Jupyter notebook with the code. The repo is here: https://github.com/jamesdeluk/data-science/tree/main/Projects/podcast-sentiment-and-topics-analysis
Initialisation
First I got all the files:
file_paths = [os.path.join('transcripts', file) for file in os.listdir('transcripts') if file.endswith('.txt')]
I’ll want to get rid of stop words later, so I built the list now. It’s based on the NLTK set. Below is the final list, including those I added to as I re-ran the analysis, words irrelevant to sentiment or topic analysis (such as names):
custom_stopwords = set(stopwords.words('english') +
["like", "know", "yeah", "right", "really", "also", "get", "way", "thing", "one", "would", "people", "time", "gon", "wan", "na",
"patrick", "christopher", "juan", "jeff", "bob", "emma", "jane", "rob", "craig", "todd", "chris", "charlie", "david", "liam", "heather", "anna", "dave", "pete", "bonnie", "nancy", "john", "nate", "wendy", "mike", "seymour", "aaron", "colleen", "abe", "dolores", "helga", "brad", "erin", "andrew", "robin", "carl", "sam", "anne", "joanna", "rachel", "noelle", "kent",
"Feedback Friday", "Feedback", "Friday", "Jordan Harbinger", "Jordan", "Harbinger", "Gabriel Mizrahi", "Gabe", "Gabriel", "Mizrahi"])
I also initialised some holding lists:
all_scores = []
all_episodes = []
Sentiment analysis
I’ll be using NLTK and VADER for the sentiment analysis.
I started by looping through each file, and getting the episode number from the filename. I often use tqdm to get a nice visual progress bar:
for transcript in tqdm(file_paths):
episode_number = transcript.split('\\')[1].split('.')[0]
with open(transcript, 'r') as f:
text = f.read()
Next came pre-processing. I removed the first line (the title), the timestamps and speaker names, an auto-generation warning, the ads (thanks for using the same phrases each time, Jordan!), and the outro. This isn’t perfect, but it’s good enough for my use. I also converted it all to lower case, to avoid a word at the start of a sentence being considered different to the same word mid-sentence:
# Preprocess text for sentiment analysis
text = text.split('\n\n')[1:] # Remove first line
text = [re.sub(r"^\[\d{2}:\d{2}:\d{2}\] [^:]+: ", "", item) for item in text] # Remove timestamps and speaker names
text = ' '.join(text) # Rejoin
text = re.sub(r"This transcript is yet untouched by human hands. Please proceed with caution as we sort through what the robots have given us. We appreciate your patience!", "", text)
text = re.sub(r"we'll be right back.*?back to feedback friday", "", text, flags=re.IGNORECASE) # Remove ads
text = re.sub(r"Go back and check out.*", "", text) # Remove outro
text = text.lower() # Convert to lowercase
Tokenise (i.e. split, but more intelligently than split()) the sentences with NLTK:
sentences = sent_tokenize(text)
Initialise the VADER analyser (yes, I stuck to US spelling):
analyzer = SentimentIntensityAnalyzer()
I also created some more holding lists/dictionaries (not shown).
To get the polarity scores, I looped through the sentences. They come as a dictionary, so I split them and saved them into a list along with the episode number and sentence:
for sentence in sentences:
scores = analyzer.polarity_scores(sentence)
all_scores.append({'Episode':episode_number, 'Sentence':sentence, 'Score_Pos':scores["pos"], 'Score_Neu':scores["neu"], 'Score_Neg':scores["neg"], 'Score_Com':scores["compound"]})
While I have the document open(), I’ll get it ready for LDA. LDA is latent Dirichlet allocation, a tool for extracting topics and themes from text. I removed non-words, split the sentences into words (tokenised), lemmatised (reduced words to their simplest form, e.g. talking → talk), removed stop words and short words (such as “a”, “in”, “he”, etc), and finally added these tokens into the big list:
# Preprocess text for LDA
text = re.sub(r'\W', ' ', text) # Remove non-words
tokens = word_tokenize(text)
lemmatizer = WordNetLemmatizer()
tokens = [lemmatizer.lemmatize(word) for word in tokens if word not in custom_stopwords and len(word) > 2]
all_episodes.append(tokens)
Insights
As this is mostly plotting and filtering and sorting, I won’t include the majority of the code here, but it’s in the repo if you want to see it.
What were the most positive and negative sentences? The ones with Score_pos of 1.0 were typically short ones such as “great” and “yeah”. Not useful. So I filtered for sentences longer than 10 words:
longer_sentences = all_scores_df[all_scores_df["Sentence"].apply(lambda x: len(x.split()) > 10)]
Most positive sentence:
beyond that, my dream employee is also positive, flexible, self-directed, curious, passionate. (0.653)
Most negative sentence:
reducing arrests and protecting low level criminals, or protecting victims of violent people? (0.651)
The score is in parenthesis. No sentences are particularly positive or negative (i.e. they’re all 0.6XX). The most positive is probably a good maxim to keep in mind. The negative one is about reducing the bad things… But it’s still talking about bad stuff.
Based on the compound score:
Most positive sentence (compound):
but from where i'm sitting, your goals, your values, your mindset, they're leading you toward greater freedom and authenticity and happiness, and away from parents who, despite their somewhat good intentions, do not seem to have your joy at heart at all. (0.983)
Most negative sentence (compound):
perhaps well-intentioned, but often neglectful and irresponsible mother or intervene in a way that causes more chaos in heather and jane's lives, and puts jane in a possibly slash probably worse situation, or at least creates more problems for them to deal with. (0.983)
Higher scores and longer sentences. They feel stronger than the positives and negatives above.
And the mean scores? For all the results, and when excluding “perfect” scores (i.e. 0.0 and 1.0):
Mean positive score: 0.167
(excluding perfect scores): 0.269
Mean negative score: 0.067
(excluding perfect scores): 0.219
Quite low. And, naturally, once I’ve started seeing numbers, I want to make plots.
First, I went crazy and plotted everything:
See why I removed the 0.0s and 1.0s above? Regardless, a big spread, mostly skewed towards the lower end (i.e. less strong - not more negative).
Next, mean and positive score - the main thing I was curious about when I started this project:
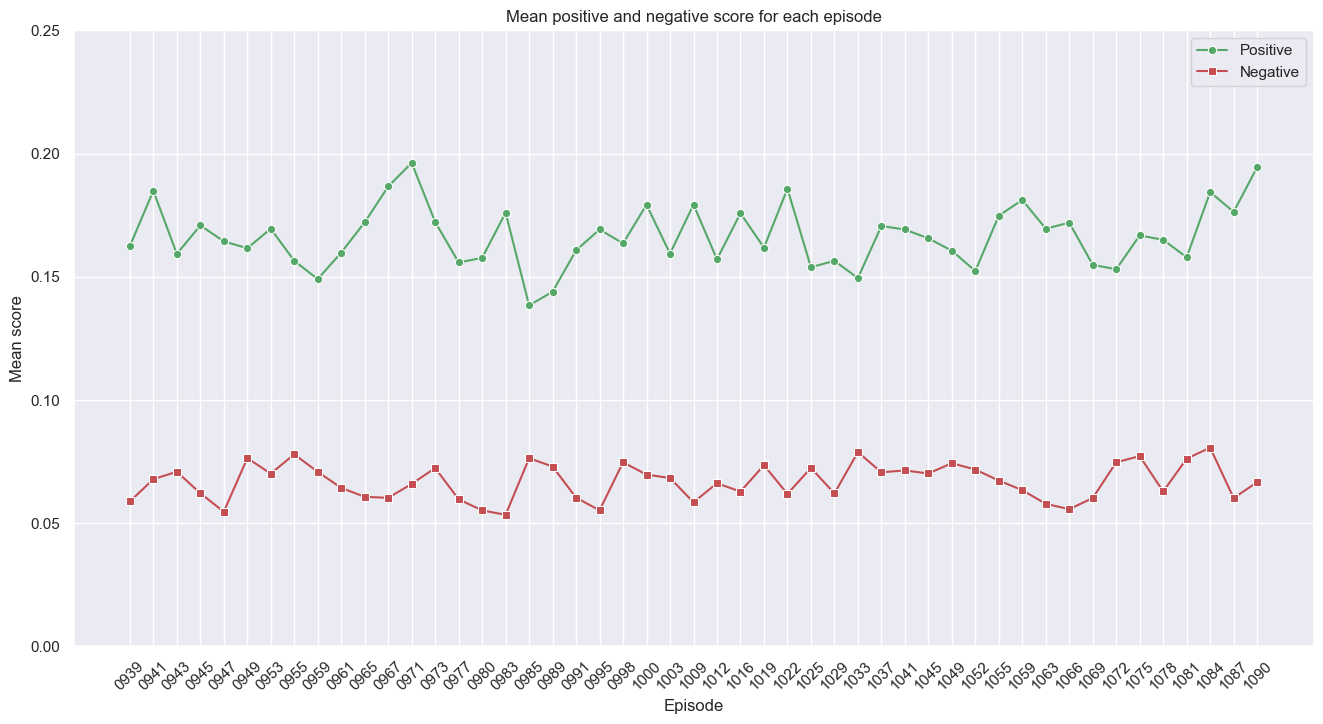
Looks like all episodes are more positive than negative! A bit of a surprise to me. That said, similar to above, all the scores are quite low - the range of available scores goes from 0.0 to 1.0, remember, and none here are over 0.2.
Based on this, what’s the mean compound score per episode? 1.0 is positive, -1.0 is negative:
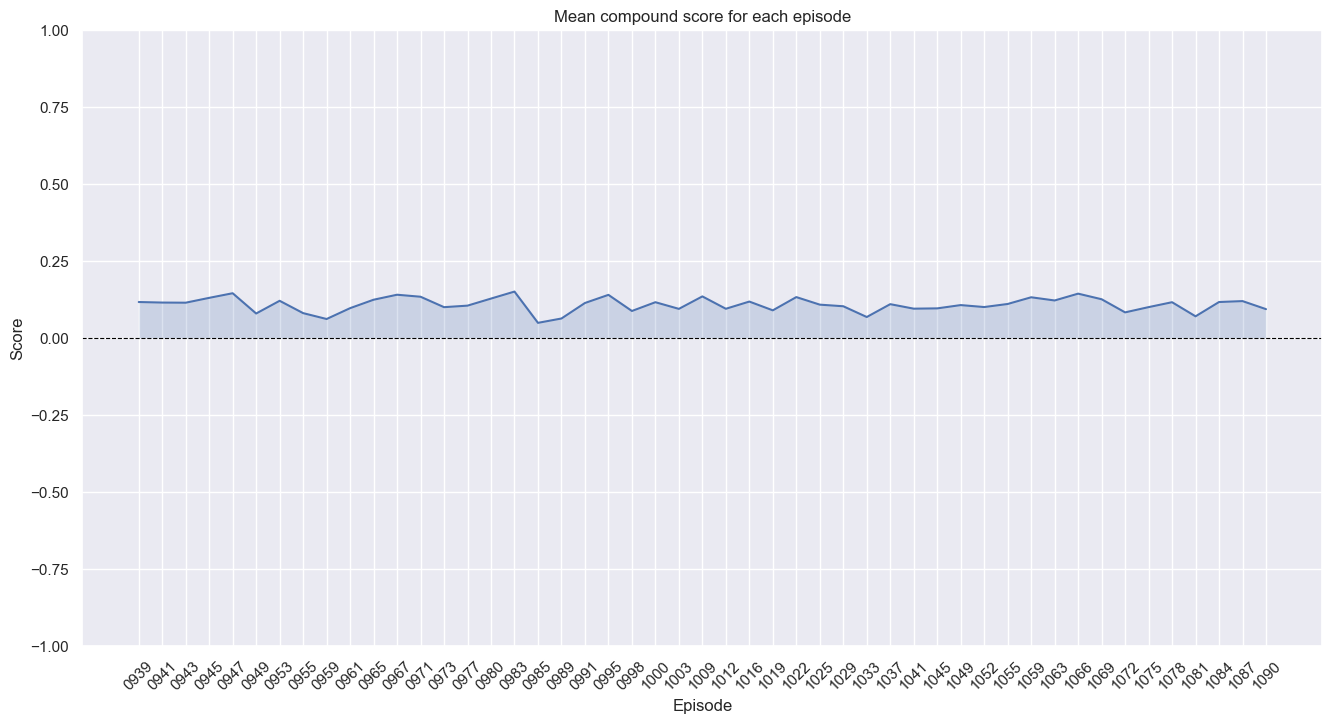
Pretty neutral overall, but all on the positive side.
And what about time-wise? Plot all the episodes on the same x-axis, with a low alpha (i.e. high transparency), to see if there are trends such as episodes starting positive and ending negative, or vice versa:
Too much to get any useful insights - although we can see the episodes vary in length, with most having fewer than 1200 sentences, but at least two over 1500.
I next looped through all the episodes and plotted them individually. I’m not going to show all 50-odd here. Here’s episode 1000, as an example:
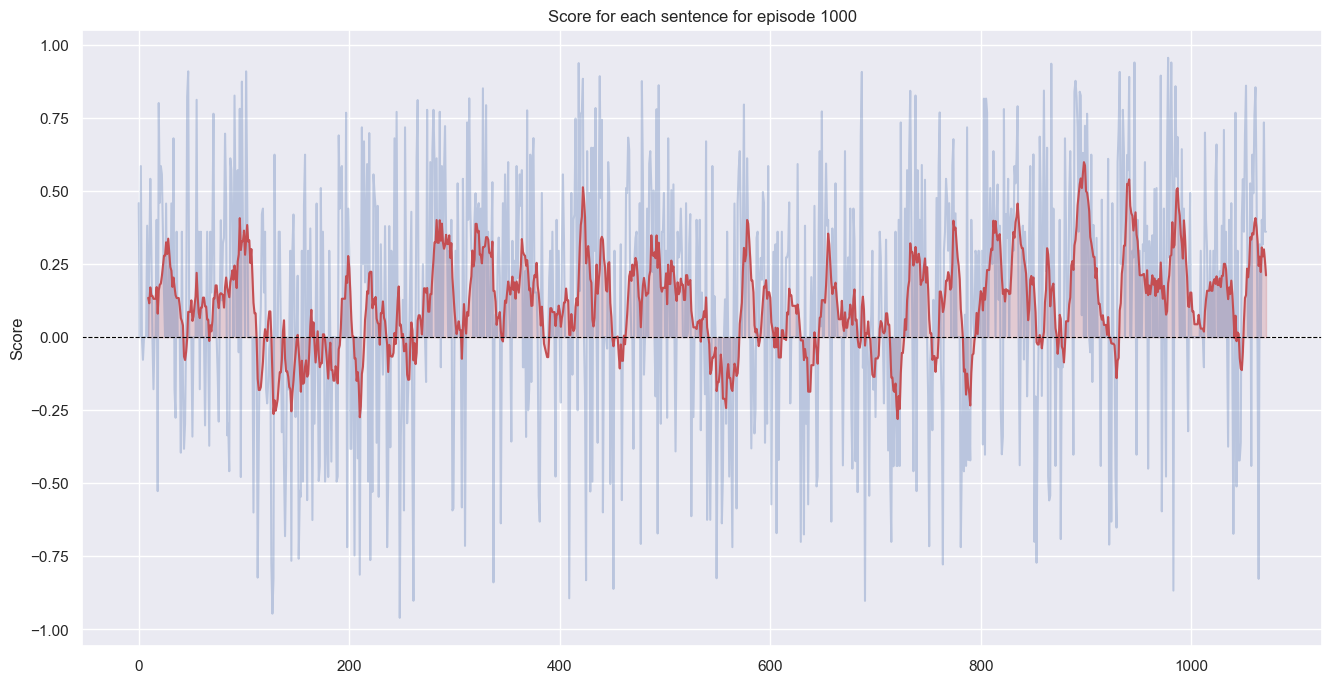
The red is a 10-sentence rolling average. A lot of up and down, and occasionally the episode gets a bit negative, but it’s mostly positive.
LDA
Now for LDA, to find common topics across the FBF episodes. Again, to me, it felt like there was a lot of abuse and addiction - let’s see if I was wrong about this too.
I’m using Gensim and pyLDAvis for this.
First, get bigrams (two word combinations) and trigrams (three word combinations):
bigram = Phrases(all_episodes, min_count=3, threshold=10)
trigram = Phrases(bigram[all_episodes], threshold=10)
bigram_mod = Phraser(bigram)
trigram_mod = Phraser(trigram)
all_episodes = [trigram_mod[bigram_mod[episode]] for episode in all_episodes]
Phrases takes the all_episodes created earlier and looks for bigrams that appear at least 3 times (min_count) and fulfil a threshold of 10 (a statistical model to determine whether to form a group; 10 is the default setting). The trigrams are made using the bigrams as an input. Phraser converts the Phrasess into the more efficient Phraser object. Finally, these models are applied to each episode within the all_episodes list, which adds the bigrams and trigrams to the list.
Next, creating the corpus.
dictionary = corpora.Dictionary(all_episodes)
dictionary.filter_extremes(no_below=5, no_above=0.5)
corpus = [dictionary.doc2bow(episode) for episode in all_episodes]
The custom dictionary maps each word in all_episodes to a numerical ID, as computers work in numbers, not letters. I then threw away uncommon words, those appearing in fewer than 5 episodes (~a tenth of the total), and those appearing in over 50% of the episodes. These are the defaults, and it’s good to have a play with these values - if no_below is too low, there may be noise from rare words, and if no_above is too high, only common/generic words may show, giving no insight into the themes. The bag of words (bow) is a list of lists (one per episode) of tuples, with each word ID and the number of times it appears (i.e. the word frequencies).
Finally, time to build the LDA model:
lda_model = LdaModel(corpus, num_topics=5, id2word=dictionary, passes=50, random_state=42)
It uses the corpus and dictionary, and takes 50 passes to try and find 5 topics.
Before I look at the topics it found, I checked the coherence score. 1.0 would be a perfect score, suggesting the groupings are good; 0.0 is terrible.
coherence_model_lda = CoherenceModel(model=lda_model, texts=all_episodes, dictionary=dictionary, coherence='c_v')
coherence_score = coherence_model_lda.get_coherence()
It wasn’t great, around 0.6.
We can see the topics by looping:
for idx, topic in lda_model.print_topics(-1):
print(f"Topic {idx}: {topic}")
But, before I show you the results, I did a little manual grid search, using loops, testing various values of no_below and no_above, to find the best score. The best score was only just over 0.7, for parameters of 0 and 0.1 respectively. Instinctively these values seem low, but let’s roll with it.
Now let’s look at the topics:
Topic 1: 0.003*"goat" + 0.002*"octopus" + 0.002*"chef" + 0.002*"prenup" + 0.002*"badminton" + 0.001*"obsession" + 0.001*"mistress" + 0.001*"sex_addiction" + 0.001*"statute_limitation" + 0.001*"charity"
Topic 2: 0.003*"barber" + 0.002*"postpartum_psychosis" + 0.002*"italian" + 0.002*"irs" + 0.002*"triggernometry" + 0.002*"audible" + 0.002*"presentation" + 0.001*"creditor" + 0.001*"trans" + 0.001*"mural"
Topic 3: 0.002*"student_loan" + 0.002*"narcolepsy" + 0.002*"probation" + 0.002*"handsome_boy_number" + 0.002*"puppy" + 0.002*"overtime" + 0.002*"accommodation" + 0.002*"barnes_noble" + 0.002*"coup" + 0.002*"firearm"
Topic 4: 0.003*"bail_reform" + 0.003*"investor" + 0.002*"hhc" + 0.002*"heroin" + 0.002*"squid" + 0.002*"tokyo" + 0.002*"fraga" + 0.002*"ukraine" + 0.002*"khoddam" + 0.001*"tea_ceremony"
Topic 5: 0.003*"dumpster" + 0.002*"dyslexia" + 0.002*"hot_tub" + 0.002*"ebay" + 0.001*"elder" + 0.001*"transcript" + 0.001*"dental" + 0.001*"bracelet" + 0.001*"tenant" + 0.001*"bead_guy"
A badminton obsessed chef with a sex addition to his mistress (and a goat and an octopus?) An Italian trans barber with postpartum psychosis in trouble with creditors and the IRS. A coup on a book store using a firearm during a bout of narcolepsy brought on by student loan fears (he’s now on probation). A tea ceremony featuring heroin and squids in Tokyo and Ukraine, ran by investors passionate about bail reform. A dumpster hot tub ran by an elder dyslexic dental specialist who also sells bracelets on eBay.
OK, that’s not quite how these work, but it’s fun.
We can also create a pretty visual:
lda_vis = gensimvis.prepare(lda_model, corpus, dictionary)
pyLDAvis.save_html(lda_vis, 'lda_visualisation.html')
It creates an HTML webpage, which you can view here: LDA visualisation
This is quite complicated; it plots how close the different topics are to each other and their overlap, along with the salient terms (roughly the likelihood of it being in a topic) and their relevance to an individual topic. Topics 3 and 4 overlap a lot. Goats and octopus are very common… But perhaps that’s meant to be GOAT (i.e. greatest of all time)? Topics such as bail reform, dumpsters, psychosis, loans, and investors are also prominent.
Conclusion
It looks like the podcasts are less negative than I thought. Although the topics themselves are often negative, Jordan and Gabe are often positive in their appraisal of the situations - although, overall, mostly neutral.
As for the topics, I wouldn’t say these results are particularly stellar. While this was the result with the highest coherence score, the topics don’t seem accurate based on actually listening to the episodes. Changin the no_ parameters returned topics including grief, scams, porn, debt, alcohol, recovery, and lots more - including lots more cats and dogs. I’d also try not lower-casing, to see if that makes a difference (for example, with the goat/GOAT question). I also believe I’d get better results with more topics - after all, this is 50 episodes of, say, 5 stories each, so compressive 250 stories into 5 themes seems a bit optimistic.
Either way, this was a fun little project!