
Wednesday, December 11, 2024 | 26 minutes
Disaster Tweets Natural Language Processing
Intro
I have a dataset of tweets, which includes whether they are referring to a disaster or not. The goal is to build a model that takes a tweet and predicts if it is a disaster. This could be useful during an actual disaster to ensure only the most relevant ones are shown to emergency responders.
The full code for this project can be found on my GitHub: https://github.com/jamesdeluk/data-projects/tree/main/nlp-with-disaster-tweets
Exploring and cleaning the data
I started by looking at the raw data in a text editor; as it was only a few hundred kilobytes, it was easy enough to do:

The first column is the ID, the second is a keyword (which looks to have some consistency), third the location (without consistency - different formatting, some are not physical places, and some without data), the text of the tweet (which can contain URLs and @s and #tags), and the target (whether the tweet referred to a real disaster or not).
I imported the data, then got some basic info:
df_train = pd.read_csv('train.csv')
df_train.shape
There are 7613 rows with the 5 columns we saw above.
df_train.isnull().sum()
| id | 0 |
|---|---|
| keyword | 61 |
| location | 2533 |
| text | 0 |
| target | 0 |
Lots of empty locations, and a few empty keywords.
df_train.duplicated().sum()
No duplicates.
print(f'Disasters:\t{df_train[df_train.target==1].shape[0]} ({round(df_train[df_train.target==1].shape[0]/df_train.shape[0]*100,1)}%)')
print(f'Not disasters:\t{df_train[df_train.target==0].shape[0]} ({round(df_train[df_train.target==0].shape[0]/df_train.shape[0]*100,1)}%)')
Disasters: 3271 (43.0%)
Not disasters: 4342 (57.0%)
Fairly close to a 50:50 split, but the dataset does have about 30% more tweets not referring to disasters than ones that do.
Now to look at the individual columns.
Keywords
First, keywords.
df_train['keyword'].nunique()
221 unique keywords, so on average each one will have 35 tweets. Breaking it down by keyword and by target:
df_train[df_train['target']==1][['keyword','target']].groupby('keyword').value_counts().sort_values(ascending=False).head(10)
df_train[df_train['target']==0][['keyword','target']].groupby('keyword').value_counts().sort_values(ascending=False).head(10)
| keyword | target | count | keyword | target | count | |
|---|---|---|---|---|---|---|
| derailment | 1 | 39 | body%20bags | 0 | 40 | |
| outbreak | 1 | 39 | armageddon | 0 | 37 | |
| wreckage | 1 | 39 | harm | 0 | 37 | |
| debris | 1 | 37 | deluge | 0 | 36 | |
| oil%20spill | 1 | 37 | ruin | 0 | 36 | |
| typhoon | 1 | 37 | wrecked | 0 | 36 | |
| rescuers | 1 | 32 | explode | 0 | 35 | |
| suicide%20bomb | 1 | 32 | fear | 0 | 35 | |
| suicide%20bombing | 1 | 32 | twister | 0 | 35 | |
| evacuated | 1 | 32 | siren | 0 | 35 |
Derailments are bad, but surprisingly, body bags are not. Armageddon is also typically fine.
What about the ratio of disaster to non-disaster tweets by keyword? I took the top 5% for each:
df_train.groupby('keyword', as_index=False).agg(target_mean=('target','mean'), keyword_count=('target','size')).query('target_mean > 0.95').sort_values('target_mean', ascending=False).round(3)
df_train.groupby('keyword', as_index=False).agg(target_mean=('target','mean'), keyword_count=('target','size')).query('target_mean < 0.05').sort_values('target_mean', ascending=False).round(3)
| keyword | target_mean | keyword_count | keyword | target_mean | keyword_count | |
|---|---|---|---|---|---|---|
| debris | 1 | 37 | aftershock | 0 | 34 | |
| derailment | 1 | 39 | body%20bags | 0.024 | 41 | |
| wreckage | 1 | 39 | ruin | 0.027 | 37 | |
| outbreak | 0.975 | 40 | blazing | 0.029 | 34 | |
| oil%20spill | 0.974 | 38 | body%20bag | 0.03 | 33 | |
| typhoon | 0.974 | 38 | electrocute | 0.031 | 32 | |
| suicide%20bombing | 0.97 | 33 | ||||
| suicide%20bomber | 0.968 | 31 |
Quite similar to above. All tweets mentioning debris, derailment, and wreckage are bad; all tweets mentioning aftershock are okay.
Locations
Next column.
df_train['location'].nunique()
This gives 3341 - so an average of just over 2 tweets per location. Very little consistency, as we saw from the look at the CSV. Similar to above, let’s get some stats:
df_train[df_train['target']==1][['location','target']].groupby('location').value_counts().sort_values(ascending=False).head(10)
df_train[df_train['target']==0][['location','target']].groupby('location').value_counts().sort_values(ascending=False).head(10)
| location | target | count | location | target | count | |
|---|---|---|---|---|---|---|
| USA | 1 | 67 | New York | 0 | 55 | |
| United States | 1 | 27 | USA | 0 | 37 | |
| Nigeria | 1 | 22 | London | 0 | 29 | |
| India | 1 | 20 | United States | 0 | 23 | |
| Mumbai | 1 | 19 | Los Angeles, CA | 0 | 18 | |
| UK | 1 | 16 | Canada | 0 | 16 | |
| London | 1 | 16 | Kenya | 0 | 15 | |
| New York | 1 | 16 | Everywhere | 0 | 12 | |
| Washington, DC | 1 | 15 | UK | 0 | 11 | |
| Canada | 1 | 13 | Florida | 0 | 11 |
There are some immediate issues here. USA and United States are presumably the same. There’s a mix of cities (Los Angeles), states (Florida), countries (United States), and ones that could be either (is it New York state or New York City?), and others (Everywhere). There’s also the issue of towns and cities with the same names - the dataset includes “Manchester, England”, “Manchester, UK”, “Manchester, NH”, and just “Manchester”.
What about percentages?
df_train.groupby('location', as_index=False).agg(target_mean=('target','mean'), keyword_count=('target','size')).query('target_mean > 0.95').sort_values('target_mean', ascending=False).round(3)
df_train.groupby('location', as_index=False).agg(target_mean=('target','mean'), keyword_count=('target','size')).query('target_mean < 0.05').sort_values('target_mean', ascending=False).round(3)
This isn’t great:
| location | target_mean | keyword_count | location | target_mean | keyword_count | |
|---|---|---|---|---|---|---|
| åø_(?)_/åø | 1 | 1 | åÊ(?Û¢`?Û¢å«)?? | 0 | 1 | |
| 1 | 1 | Glasgow | 0 | 1 | ||
| News | 1 | 1 | Melbourne, Australia | 0 | 1 | |
| 616 Û¢ Kentwood , MI | 1 | 1 | å_ | 0 | 1 | |
| ? ??????? ? ( ?? å¡ ? ? ? å¡) | 1 | 1 | Û¢OlderCandyBloomÛ¢ | 0 | 1 | |
| … | … | … | … | … | … | |
| 1199 rows × 3 columns | 1828 rows × 3 columns |
There are almost 3000 rows with a “perfect” score - but that’s because they all only have 1 tweet. And, as you can see, a lot of the locations are invalid. Instead, I changed the query() from target_mean to 'keyword_count > 5' (I chose 5 fairly arbitrarily):
df_train.groupby('location', as_index=False).agg(target_mean=('target','mean'), keyword_count=('target','size')).query('keyword_count >= 5').sort_values(['target_mean','keyword_count'], ascending=[False,False]).head(5).round(3)
df_train.groupby('location', as_index=False).agg(target_mean=('target','mean'), keyword_count=('target','size')).query('keyword_count >= 5').sort_values(['target_mean','keyword_count'], ascending=[True,False]).head(5).round(3)
| location | target_mean | keyword_count | location | target_mean | keyword_count | |
|---|---|---|---|---|---|---|
| Mumbai | 0.864 | 22 | 304 | 0 | 9 | |
| India | 0.833 | 24 | Pennsylvania, USA | 0 | 7 | |
| Paterson, New Jersey | 0.833 | 6 | Morioh, Japan | 0 | 6 | |
| Oklahoma City, OK | 0.833 | 6 | Coventry | 0 | 5 | |
| Pedophile hunting ground | 0.833 | 6 | Indiana | 0 | 5 |
Looks like most Mumbai and India tweets are disasters, but Pennsylvania and Morioh are safe. Not sure where 304 is.
It would be good to clean these up. I tried fuzzywuzzy, but that caused issues with the locations such as New York (state or city?) and Manchester (UK or USA?). Manual fixing seems like it would be the most effective option, but beyond small fixes (e.g. USA to United States), it would be best to have a unified structure, splitting City, State, and Country into their own features (so correlations between Mumbai and India could be made). This would be a big task though, so for now, I opted against it - can I get good enough results without fixing this?
Text
This is the big one.
Cleaning
As is often the case with text data, it needed cleaning. I created a bunch of functions, which I could then easily apply to the feature for mass cleaning.
First, I noticed some of the tweets went over multiple lines, so I needed to remove the newline characters:
def remove_newlines(text): return re.sub(r'\n', ' ', text).strip()
Second, there were some HTML entities, such as ‘&’ as & and ‘>’ as >. The html package can fix these:
def fix_html_entities(text): return html.unescape(text)
Third, I wanted to extract the hashtags (#s), handles (@s), and URLs (https). The below function can handle all three through the second argument. It returns the text with the element removed, the elements removed as a single lowercase string, and the number of elements:
def extract_elements(text, element_type):
patterns = { 'hashtags': r'#[A-Za-z0-9-_]+',
'handles': r'@[A-Za-z0-9-_]+',
'urls': r'https?://t.co/[A-Za-z0-9]{10}' }
pattern = re.compile(patterns[element_type])
elements = pattern.findall(text)
n = len(elements)
elements_str = ' '.join(elements).lower()
new_text = pattern.sub('', text)
return new_text.strip(), elements_str, n
Then I applied all these to the text column, and outputted the results to a new text_clean column:
df_train['text_clean'] = df_train['text'].apply(lambda x: remove_newlines(x))
df_train['text_clean'] = df_train['text_clean'].apply(lambda x: fix_html_entities(x))
df_train[['text_clean', 'hashtags', 'n_hashtags']] = df_train['text_clean'].apply(lambda x: extract_elements(x,'hashtags')).apply(pd.Series)
df_train[['text_clean', 'handles', 'n_handles']] = df_train['text_clean'].apply(lambda x: extract_elements(x,'handles')).apply(pd.Series)
df_train[['text_clean', 'urls', 'n_urls']] = df_train['text_clean'].apply(lambda x: extract_elements(x,'urls')).apply(pd.Series)
A sample of the before and after:
| text | text_clean | hashtags | n_hashtags | handles | n_handles | urls | n_urls |
|---|---|---|---|---|---|---|---|
| #breaking #news Global precipitation measureme… | Global precipitation measurement satellite cap… | [#breaking, #news] | 2 | [@nasahurricane] | 1 | [http://t.co/20DNcthr4D] | 1 |
I could go one step further and one-hot encode these new columns into their own features. However, this only creates binary features (i.e. yes or no), and loses independence (whereas in reality #breaking and #news are related). This would add 9000 features, which could dramatically increase the modelling time. Instead, I’ll vectorise… Later. For now, let’s look into some word and phrase frequencies.
Frequencies of n-grams
Some quick definitions. n-grams are strings of words of length n. A unigram is a string of words of length 1 - in other word, a single word. Bigrams are strings of two words.
First, I wanted to see how many unique words were in the text. Join the individual text strings, make it all lower case (for later), split into words, make it into a set to remove duplicates, then take the length:
len(set(' '.join(df_train['text_clean']).lower().split()))
19134 unique words - quite a few.
OK, frequencies. I wanted to assess by target, so, similar to above, I joined them, and saved them as variables:
disaster_clean_text = ' '.join(df_train[df_train['target']==1]['text_clean']).lower()
notdisaster_clean_text = ' '.join(df_train[df_train['target']==0]['text_clean']).lower()
Which words are the most common in each set? The process starts with tokenisation, which is splitting a piece of text into smaller units, be they words, sentences, phrases, etc. I started with words, using nltk’s word_tokenize, ignoring stop words and making sure it uses alphabet letters (i.e. no numbers or punctuation):
disaster_tokens = [w for w in word_tokenize(disaster_clean_text) if (w not in nltkstopwords) & (w.isalpha())]
notdisaster_tokens = [w for w in word_tokenize(notdisaster_clean_text) if (w not in nltkstopwords) & (w.isalpha())]
Then I used nltk’s FreqDist:
top_disaster_tokens = FreqDist(disaster_tokens).most_common(20)
top_notdisaster_tokens = FreqDist(notdisaster_tokens).most_common(20)
display(pd.DataFrame(top_disaster_tokens, columns=['Disaster Token', 'Frequency']).head(10))
display(pd.DataFrame(top_notdisaster_tokens, columns=['Non-Disaster Token', 'Frequency']).head(10))
| Disaster Token | Frequency | Non-Disaster Token | Frequency | |
|---|---|---|---|---|
| fire | 175 | like | 253 | |
| via | 121 | new | 168 | |
| disaster | 111 | get | 162 | |
| california | 107 | one | 129 | |
| police | 106 | body | 110 | |
| suicide | 104 | would | 105 | |
| people | 103 | via | 97 | |
| like | 93 | video | 94 | |
| killed | 92 | got | 92 | |
| storm | 85 | people | 92 |
Tweets about disasters often include disaster-related vocab, such as fire, storm, and suicide. Non-disasters include more general words, such as new, video, people. Some are in both, such as like and via.
Which words are exclusive to one top-20, but not the other?
top_disaster_words = [w for w,f in top_disaster_words]
top_nondisaster_words = [w for w,f in top_nondisaster_words]
display(', '.join([w for w in top_disaster_words if w not in top_nondisaster_words]))
display(', '.join([w for w in top_nondisaster_words if w not in top_disaster_words]))
Disaster-not-non-disaster include fire, disaster, california, police, suicide, killed, storm, crash, news, fires, families, train, buildings, bomb, two, and attack.
Non-disaster-not-disaster include new, get, one, body, would, video, got, love, know, back, time, see, full, day, going, and ca.
Next, bigrams. I started by generating the lists of bigrams, using the tokens generated earlier:
disaster_bigrams = [' '.join(b) for b in list(bigrams(disaster_tokens))]
nondisaster_bigrams = [' '.join(b) for b in list(bigrams(notdisaster_tokens))]
The default output of bigrams() is a generator; converting it to a list makes it a list of tuples; I just wanted a list of strings, hence list comprehension.
After that, the code is similar to unigrams:
top_disaster_bigrams = FreqDist(disaster_bigrams).most_common(20)
top_nondisaster_bigrams = FreqDist(nondisaster_bigrams).most_common(20)
display(pd.DataFrame(top_disaster_bigrams, columns=['Disaster Token', 'Frequency']).head(10))
display(pd.DataFrame(top_nondisaster_bigrams, columns=['Disaster Token', 'Frequency']).head(10))
top_disaster_bigrams = [w for w,f in top_disaster_bigrams]
top_nondisaster_bigrams = [w for w,f in top_nondisaster_bigrams]
display(' | '.join([w for w in top_disaster_bigrams if w not in top_nondisaster_bigrams]))
display(' | '.join([w for w in top_nondisaster_bigrams if w not in top_disaster_bigrams]))
| Disaster Token | Frequency | Non-Disaster Token | Frequency | |
|---|---|---|---|---|
| suicide bomber | 59 | cross body | 38 | |
| northern california | 41 | liked video | 34 | |
| oil spill | 38 | gon na | 32 | |
| burning buildings | 35 | wan na | 30 | |
| suicide bombing | 32 | body bag | 26 | |
| california wildfire | 32 | body bagging | 23 | |
| bomber detonated | 30 | burning buildings | 23 | |
| homes razed | 29 | full read | 22 | |
| latest homes | 28 | looks like | 21 | |
| razed northern | 28 | feel like | 20 |
Suicide bombers, oil spills, and burning buildings are bad. As is Northern California (presumably the fires). Body bags, cross body, and gon na (gonna?) and wan na (wanna?) are fine. None of the bigrams in the top 20 of the disaster set were in the non-disaster one and vice versa.
Hashtags
How many do we have in total? Similar code to the total number of unique words above, we find 1926 unique hashtags.
What are the most common ones for disasters and non-disasters? Again I can reuse the code from above; however, given the column has them combined as a string, it might be less reliable than if they contained only a single hashtag. Regardless:
| hashtags | target | count | hashtags | target | count | |
|---|---|---|---|---|---|---|
| #hot #prebreak #best | 1 | 13 | #hot #prebreak #best | 0 | 17 | |
| #news | 1 | 12 | #gbbo | 0 | 11 | |
| #earthquake | 1 | 8 | #nowplaying | 0 | 10 | |
| #worldnews | 1 | 8 | #beyhive | 0 | 8 | |
| #hiroshima | 1 | 8 | #directioners | 0 | 7 | |
| #wx | 1 | 7 | #dubstep #trapmusic #dnb #edm #dance #ices | 0 | 7 | |
| #antioch | 1 | 6 | #animalrescue | 0 | 7 | |
| #bestnaijamade | 1 | 6 | #handbag #womens | 0 | 5 | |
| #okwx | 1 | 6 | #islam | 0 | 5 |
News, earthquakes, and Hiroshima and news are often bad, and the Great British Bake Off, Now Playing, and Beyoncé are good. I’d imagine it’s one avid poster who likes the #hot #prebreak #best combination, regardless of what they’re tweeting about.
Handles
2316 unique handles. And:
| handles | target | count | handles | target | count | |
|---|---|---|---|---|---|---|
| @youtube | 1 | 17 | @youtube | 0 | 44 | |
| @usatoday | 1 | 4 | @djicemoon | 0 | 7 | |
| @potus | 1 | 4 | @change | 0 | 5 | |
| @foxnews | 1 | 4 | @emmerdale | 0 | 4 | |
| @change | 1 | 4 | @mikeparractor | 0 | 4 | |
| @sharethis | 1 | 3 | @raynbowaffair @diamondkesawn | 0 | 4 | |
| @viralspell | 1 | 3 | @usatoday | 0 | 4 | |
| @smh | 1 | 3 | @worldnetdaily | 0 | 4 | |
| @nasahurricane | 1 | 3 | @justinbieber @arianagrande | 0 | 3 |
People like YouTube. Disaster tweets often mention news or political organisations, whereas non-disaster tweets mention musicians and actors.
URLs
4593 unique URLs! And:
URL shorteners are very annoying. The counts are lower than the other categories, so the same link is shared less commonly. Also, many of these links are now dead, so I can’t see where they originally went.
Summary
So, what have we found so far?
Every tweet with the keyword debris, derailment, and wreckage is a disaster. Outbreaks, oil spills, typhoons, and suicide bomber/bombing keywords are nearly always disasters, and disaster tweets often include the words fire, disaster, killed, storm, and the hashtag #earthquake. Most disaster tweets come from the USA… As do most non-disaster tweets. Most tweets coming from Mumbai and India concern a disaster; Nigeria too. A lot of disaster tweets talk about (Northern) California, and many mention news agencies.
The keyword aftershock only appears in non-disaster tweets; surprisingly, body bag(s) are also typically associated with non-disasters. As mentioned, the USA is the top source of non-disaster tweets, followed by the UK (London). Most unigrams and bigrams related to non-disasters are “boring”, giving little insight into the context of the tweet. Many mentions and hashtags relate to media such as music/musicians and movies/TV/actors.
Feature engineering
Stats
Now I’ve got an idea of what the data contains, I decided to generate some stats:
nltkstopwords = stopwords.words('english')
def char_count(text): return len(text)
def word_count(text): return len(text.split())
def unique_word_count(text): return len(set(text.split()))
def avg_word_length(text): return round(sum(len(word) for word in text.split()) / len(text.split()),3)
def punctuation_count(text): return len([n for n in text if n in string.punctuation])
def stopwords_count(text): return len([n for n in text if n in nltkstopwords])
def caps_count(text): return sum([1 for n in text if n.isupper()])
df_train['char_count'] = df_train['text_clean'].apply(lambda x: char_count(x))
df_train['word_count'] = df_train['text_clean'].apply(lambda x: word_count(x))
df_train['unique_word_count'] = df_train['text_clean'].apply(lambda x: unique_word_count(x))
df_train['avg_word_length'] = df_train['text_clean'].apply(lambda x: avg_word_length(x))
df_train['punctuation_count'] = df_train['text_clean'].apply(lambda x: punctuation_count(x))
df_train['stopwords_count'] = df_train['text_clean'].apply(lambda x: stopwords_count(x))
df_train['caps_count'] = df_train['text_clean'].apply(lambda x: caps_count(x))
These are all fairly straightforward - creating new columns with the number of characters, the number of words, the number of unique words, the average word count, the number of punctuation, the number of stop words (words such as the, a, or, me, etc), the number of capitals, and a list of repeated words. For the stop words, I used a set built into nltk, as it makes it more compatible with the future steps, and assigning it to a variable first makes the in checks much faster. The output is something that looks like this:
| char_count | word_count | unique_word_count | avg_word_length | punctuation_count | stopwords_count | caps_count |
|---|---|---|---|---|---|---|
| 58 | 12 | 12 | 3.833 | 0 | 6 | 10 |
And stats for the stats:
| char_count | word_count | unique_word_count | avg_word_length | punctuation_count | stopwords_count | caps_count | |
|---|---|---|---|---|---|---|---|
| mean | 78.132 | 13.557 | 12.995 | 4.958 | 2.828 | 4.524 | 6.23 |
| std | 32.195 | 5.908 | 5.429 | 1.079 | 3.013 | 3.419 | 9.246 |
| min | 4 | 1 | 1 | 2 | 0 | 0 | 0 |
| max | 157 | 31 | 29 | 19.333 | 55 | 19 | 118 |
The average tweet has 14 5-character words, 5 of which are stopwords, with one word repeated (i.e. 13 words are unique). It has 3 punctuation markers (!!!) and SIX CAPitals.
Polynomial features
I wanted to add polynomial features for these numerical features, which can be done through the PolynomialFeatures module in sklearn. I created a function and a separate poly variable to ensure the same transformation is done to the testing data later:
def poly_features(df, poly=None):
cols = ['n_handles','n_hashtags','n_urls','char_count','word_count','unique_word_count','avg_word_length','punctuation_count','stopwords_count','caps_count']
numerical_features = df[cols]
if poly is None:
poly = PolynomialFeatures(degree=2, include_bias=False)
poly.fit(numerical_features)
poly_features = poly.transform(numerical_features)
poly_feature_names = poly.get_feature_names_out(numerical_features.columns)
df_poly = pd.DataFrame(poly_features, columns=poly_feature_names, index=df.index)
df_poly = df_poly.loc[:, ~df_poly.columns.isin(numerical_features.columns)]
return pd.concat([df, df_poly], axis=1), poly
df_train, poly = poly_features(df_train)
For a degree of 2, as I chose, it multiplies every column by every column. Extending the example above, some of the output columns are:
| char_count^2 | char_count word_count | char_count unique_word_count | char_count avg_word_length | char_count punctuation_count | char_count stopwords_count | char_count caps_count |
|---|---|---|---|---|---|---|
| 3364 | 696 | 696 | 222.314 | 0 | 348 | 580 |
I was curious if there was any correlation between the numerical features we have so far and the target, so I did a simple Pearson correlation:
df_train.select_dtypes(include=['number']).drop('id', axis=1).corr()['target'].drop('target').sort_values(ascending=False).round(3)
| n_urls char_count | 0.228 |
|---|---|
| n_urls avg_word_length | 0.212 |
| n_urls unique_word_count | 0.205 |
| … | … |
| stopwords_count | -0.099 |
| n_handles | -0.103 |
| stopwords_count^2 | -0.113 |
We’d be interested in the largest absolute values, so the most positive and most negative. However, the largest correlate is 0.228, which is pretty weak. It doesn’t mean they won’t help the regressor, though, so I’ll keep them in for now.
Category encoding
The keyword and location categories are still text; for the logistic regression I’ll be using they need to be numerical. One way of doing this is category encoding. There are multiple tools to do this; one, using the category_encoders package, another using sklearn. For the first:
features = ['keyword', 'location']
ce_encoder = ce_TargetEncoder(cols=features, smoothing=0)
ce_encoder.fit(df_train[features],df_train['target'])
ce_transformed_df = ce_encoder.transform(df_train[features]).add_suffix('_target_ce')
df_train = df_train.join(ce_transformed_df)
And the other:
features = ['keyword', 'location']
skl_encoder = skl_TargetEncoder(categories='auto', target_type='binary', smooth='auto', cv=5, random_state=42)
skl_transformed = skl_encoder.fit_transform(df_train[features], df_train['target'])
skl_transformed_df = pd.DataFrame(skl_transformed, columns=[f"{col}_target_skl" for col in features], index=df_train.index)
df_train = df_train.join(skl_transformed_df)
The former assigns the same value to each feature, a form of smoothed mean, whereas the latter creates a few different values based on… Something that I’m still figuring out, but it’s more variable due to the out-of-fold cross validation.
For example, London:
| target | location | location_target_ce | location_target_skl |
|---|---|---|---|
| 1 | London | 0.361177 | 0.369915 |
| 0 | London | 0.361177 | 0.369915 |
| 1 | London | 0.361177 | 0.273662 |
| 0 | London | 0.361177 | 0.335522 |
| 0 | London | 0.361177 | 0.273662 |
| 1 | London | 0.361177 | 0.273662 |
| 1 | London | 0.361177 | 0.437261 |
Focussing just on the sklearn ones, grouping by the encoded value and then target:
| location_target_skl | target | count |
|---|---|---|
| 0.273662 | 0 | 2 |
| 1 | 6 | |
| 0.335522 | 0 | 3 |
| 1 | 3 | |
| 0.369915 | 0 | 5 |
| 1 | 2 | |
| 0.383659 | 0 | 8 |
| 1 | 3 | |
| 0.437261 | 0 | 11 |
| 1 | 2 |
And grouping by the target, and taking the mean of the encoded values:
| target | location_target_skl |
|---|---|
| 0 | 0.389055 |
| 1 | 0.338366 |
Feature extraction: CountVectorizer
Now’s the time to vectorise. I’ll use nltk’s CountVectorizer, which converts a collection of text to a matrix of token counts - in other words, it turns text into numbers based on their frequency. I did this for each of the three extracted element types:
vec_hashtags = CountVectorizer(min_df=4)
df_train_hashtags_vectorised = vec_hashtags.fit_transform(df_train['hashtags'])
df_train_hashtags_vectorised_df = pd.DataFrame(df_train_hashtags_vectorised.toarray(), columns=vec_hashtags.get_feature_names_out())
vec_handles = CountVectorizer(min_df=2)
df_train_handles_vectorised = vec_handles.fit_transform(df_train['handles'])
df_train_handles_vectorised_df = pd.DataFrame(df_train_handles_vectorised.toarray(), columns=vec_handles.get_feature_names_out())
vec_urls = CountVectorizer(min_df=2, token_pattern=r'https?://t.co/[A-Za-z0-9]{10}')
df_train_urls_vectorised = vec_urls.fit_transform(df_train['urls'])
df_train_urls_vectorised_df = pd.DataFrame(df_train_urls_vectorised.toarray(), columns=vec_urls.get_feature_names_out())
print(f'{df_train_hashtags_vectorised_df.shape[1]} {df_train_handles_vectorised_df.shape[1]} {df_train_urls_vectorised_df.shape[1]}')
The min_df argument is the minimum number (or percentage, if between 0 and 1) of times a token must occur to be vectorised; it’s a way of reducing the number of features. I found earlier there are ~2000 unique hashtags and handles and ~4500 unique URLs - including them all add another ~9000 features, which is too many. I wanted 100-200 each, hence the chosen min_df values; the counts can be gotten from the shape[1]. The token pattern is needed for the URL otherwise the parser might corrupt the URL - in this case, without the token pattern, the output would crop the domain, leaving only the path.
We can see how closely a hashtag/handle/URL is related to the target:
(df_train_hashtags_vectorised_df.transpose().dot(df_train['target']) / df_train_hashtags_vectorised_df.sum(axis=0)).sort_values(ascending=False)
(df_train_handles_vectorised_df.transpose().dot(df_train['target']) / df_train_handles_vectorised_df.sum(axis=0)).sort_values(ascending=False)
(df_train_urls_vectorised_df.transpose().dot(df_train['target']) / df_train_urls_vectorised_df.sum(axis=0)).sort_values(ascending=False)
1 means a strong/perfect link, 0 a weak/non-existent one. This is just an extract, sorted alphabetically; there were a lot more with both 0 and 1 as correlations, and lots in between (for example, #breakingnews had a score of 0.75, so often a disaster, but not always):
| Hashtag | Handle | URL | |||
|---|---|---|---|---|---|
| abstorm | 1 | 9newsgoldcoast | 1 | http://t.co/199t7nd0pm | 1 |
| accident | 1 | abc | 1 | http://t.co/3sicroaanz | 1 |
| africa | 1 | _minimehh | 1 | http://t.co/i27oa0hisp | 1 |
| … | … | … | … | … | … |
| technology | 0 | worldnetdaily | 0 | https://t.co/dehmym5lpk | 0 |
| soundcloud | 0 | ymcglaun | 0 | https://t.co/lfkmtzaekk | 0 |
| summerfate | 0 | zaynmalik | 0 | https://t.co/wudlkq7ncx | 0 |
Finally, I added these new features to our DataFrame:
df_train = df_train.join(df_train_hashtags_vectorised_df, rsuffix='_hashtags')
df_train = df_train.join(df_train_handles_vectorised_df, rsuffix='_handles')
df_train = df_train.join(df_train_urls_vectorised_df, rsuffix='_urls')
Feature extraction: TfidfVectorizer
This is similar, but for the text column. This will result in a lot more features, as the volume of text is far larger. ngram_range is the length of blocks of text that should be considered. min_df is again the minimum frequency a block.
vec_text = TfidfVectorizer(min_df=10, ngram_range=(1,10), stop_words='english')
df_text_clean_vectorised = vec_text.fit_transform(df_train['text_clean'])
df_text_clean_vectorised_df = pd.DataFrame(df_text_clean_vectorised.toarray(), columns=vec_text.get_feature_names_out())
print(df_text_clean_vectorised_df.shape[1])
The average tweet has 14 words, of which an average of 2 are hashtags/handles/URLs. Based on this, alongside manually looking at the dataset, I feel n-grams of up to 5 might be relevant, and ignore any that appear fewer than 10 times. This gives us 2148 features.
Again I added these to the DataFrame:
df_train = df_train.join(df_text_clean_vectorised_df, rsuffix='_text')
Modelling
Setting up
Let’s start with a basic logistic regressor:
lr = LogisticRegression(random_state=42, solver='liblinear')
lbfgs is the default, but liblinear can be better for smaller, binary models. Testing later on proved this to be the case, so I started with it here.
I needed the X (independent) and y (dependent) variables. All the features need to be numerical; the simplest way to ensure this is to drop all the non-numerical ones - plus id, as that’s irrelevant to the target. X is made from this, also dropping target; y is only target:
features_to_drop = df_train.select_dtypes(exclude=['number']).columns.to_list()
features_to_drop.extend(['id'])
X_train = df_train.drop(columns=features_to_drop+['target'])
y_train = df_train['target']
An alternative way is to pick and choose, which could be useful when tuning the model:
features_stats = ['char_count','word_count','unique_word_count','avg_word_length','punctuation_count','stopwords_count','caps_count','n_handles','n_hashtags','n_urls',]
features_polys = list(poly.get_feature_names_out())
features_te_ce = ['keyword_target_ce','location_target_ce']
features_te_skl = ['keyword_target_skl','location_target_skl']
features_cv_hashtags = list(vec_hashtags.get_feature_names_out())
features_cv_handles = list(vec_handles.get_feature_names_out())
features_cv_urls = list(vec_urls.get_feature_names_out())
features_cv = features_cv_hashtags + features_cv_handles + features_cv_urls
features_tv = list(vec_text.get_feature_names_out())
features_to_keep = features_stats + features_polys + features_te_ce + features_te_skl + features_cv + features_tv
One minor bug with this; features_tv includes a column called text. This could be confused with the original text column, so I manually dropped it, using features_to_keep.remove('text').
Then make the variables:
X_train = df_train[features_to_keep]
y_train = df_train['target']
To find the baseline, I cross-validated the (currently default) model to get the F1 score. I’ll be cross validating at each stage, so I made it into a function. I also set up a list to capture the score each time the function is run, to easily see the improvements at each stage:
cv_scores = []
def crossval(stage):
cross_val_f1 = cross_val_score(lr, X_train, y_train, cv=5, scoring='f1')
print(f'Cross-validated F1 score: {round(cross_val_f1.mean(),4)} (range = {(cross_val_f1.max()-cross_val_f1.min()).round(4)})')
cv_scores.append((stage,cross_val_f1.mean()))
crossval('Initial')
And we get 0.6647. Not great… Let’s see if we can improve it. As a quick simple test, what if we exclude features_polys? The score immediately increases to 0.8046! However, there are better ways to exclude features, which I’ll do later. So let’s stick with including the polynomial features for now.
Balancing
The first stage is data balancing. During the exploration phase, we found the ratio between disaster and non-disaster tweets was 43:57 (3271 to 4342). This isn’t too bad, but prediction mechanisms work better with a 50:50 split.
There are two ways to do this - I could throw away ~1000 of the non-disaster tweets, bringing the count of each down to 3271. Or I could “invent” new disaster tweets, bringing the total of both up to 4342. Given our dataset is relatively small, I don’t really want to make it smaller, and as it’s already fairly balanced, adding a more positives may be the better path, as not too many will need to be added as a percentage of the total.
I opted for SMOTE - Synthetic Minority Over Sampling Technique. Instead of simply duplicating some of the smaller set, it takes a more intelligent approach - it makes new data by taking multiple existing data points and, effectively, taking the average.
smote = SMOTE(random_state=42)
X_train, y_train = smote.fit_resample(X_train, y_train)
With this, our new score is 0.7343.
Scaling
Logistic regressions work better with scaled data. Currently, some features vary form 0 to 24649 (for squared character count), whereas others vary from 0 to 0.0999 (such as for the vectorised “manslaughter fatal”). The overall dataset mean is 6.7. As such, it’s a good idea to scale the features before doing the logreg - I used MinMaxScaler, so all values are between 0 and 1. It’s best to do this after data balancing such as SMOTE, otherwise synthetic values may end up outside the scaled range.
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
Our score now increases to 0.8348.
Feature selection: SelectKBest
There are a bunch of ways to do feature selection. I showed one earlier - manually picking and choosing. But with thousands of features, there are better ways.
One is SelectKBest. It uses the chi-squared distribution to select the best ‘k’ features by testing to see how closely each feature is related to the target.
selector_pipeline = Pipeline([('select',SelectKBest(score_func=chi2)), ('clf',lr)])
bayessearch_selector = BayesSearchCV(estimator=selector_pipeline, search_spaces={'select__k':(1,X_train.shape[1])}, n_iter=100, scoring='f1', cv=5, verbose=0, n_jobs=-1)
bayessearch_selector.fit(X_train, y_train)
print("Best k:", bayessearch_selector.best_params_['select__k'])
selector_kb = bayessearch_selector.best_estimator_[0]
X_train = selector_kb.fit_transform(X_train, y_train)
I used a BayesSearchCV with 100 iterations to find the best value for k. It suggested the best number was 25 - so it’s removed ~99% of our features! Our score is now a marginally-better 0.8631.
Another option would be to manually set k - for example, I could have arbitrarily said I want 1000 features:
selector_kb = SelectKBest(score_func=chi2, k=1000)
X_train = selector_kb.fit_transform(X_train, y_train)
In this case, the score still improves, but less, to 0.8595.
Feature selection: Variance threshold
I tried this but it was rubbish so I won’t even discuss it.
Feature selection: RFECV
Recursive feature elimination (with CV) is another way. It recursively removes features (step at a time - this can be a number, of a percentage if less than 1), testing after each, and through this finds the optimum number of features.
rfecv = RFECV(estimator=lr, step=1, cv=5, scoring='f1')
rfecv.fit(X_train, y_train)
print("Optimal number of features:", rfecv.n_features_)
X_train = rfecv.transform(X_train)
Given we only have 25 features after the SelectKBest, it’s unlikely we’ll get much benefit from this. It suggested dropping a further 3, down to 22, although our score is now 0.8630, so marginally worse.
Another option would be to not do the SelectKBest and simply run the RFECV. I tried this with step=1, but this this took forever - instead of a few seconds, it was still chugging away after an hour, and with no idea how much longer it would take, I cancelled it. I tried with step=5, and after about 15 minutes it resulted in only 7 features and a score of 0.8772 - however, with this few features, I’d be concerned it’s overfitting. But still, let’s continue for now.
One nice thing with RFECV is you can easily plot a graph of the number of features against the score:
plt.plot(rfecv.cv_results_['n_features'], rfecv.cv_results_['mean_test_score'])
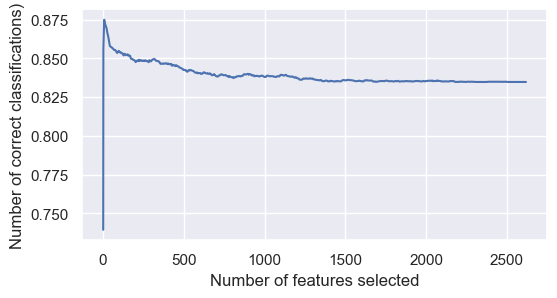
You can see the score rises rapidly, then drops off quite fast after 7, then smooths out after about 500 features.
Logistic regressor tuning
Now we have our features, we can tune our logreg. I’m a fan of BayesSearchCV, which uses Bayesian statistics over a preconfigured number of iterations to iterate towards to best parameter values:
search_spaces = [{'solver':['liblinear'], 'penalty':['l1','l2'], 'C':(0.01, 10, 'log-uniform')}]
bayessearch_lr = BayesSearchCV(LogisticRegression(random_state=42), search_spaces=search_spaces, n_iter=50, scoring='f1', cv=5, n_jobs=-1)
bayessearch_lr.fit(X_train, y_train)
print(f'Best parameters: {bayessearch_lr.best_params_}')
lr = bayessearch_lr.best_estimator_
Although the code above only mentions one solver and a smallish range of C values, I did try more; the best was always liblinear and the C value was always in that range. A smaller range during each run can be quicker, and you can use fewer iterations to get a good score.
The final model, from a C of 5.136960553873766, gave a score of 0.8812.
Testing against the real data
Now to see how it works on the test data. I have separate CSVs of the real data - test_X.csv, which has the features, and test_y.csv , which has the targets. The target file needed a little jiggling to get the series of classifications:
df_test = pd.read_csv('test_X.csv')
y_test = pd.read_csv('test_y.csv')
y_true = df_test.set_index('id').join((y_test['choose_one']=='Relevant').astype(int))['choose_one']
I needed to do all the transformations I did to df_train to df_test. Note, for the vectorisation, I had to transform and not fit_transform, as it was already fitted on the training data.
df_test['text_clean'] = df_test['text'].apply(lambda x: remove_newlines(x))
df_test['text_clean'] = df_test['text_clean'].apply(lambda x: fix_html_entities(x))
df_test[['text_clean', 'hashtags', 'n_hashtags']] = df_test['text_clean'].apply(lambda x: extract_elements(x,'hashtags')).apply(pd.Series)
df_test[['text_clean', 'handles', 'n_handles']] = df_test['text_clean'].apply(lambda x: extract_elements(x,'handles')).apply(pd.Series)
df_test[['text_clean', 'urls', 'n_urls']] = df_test['text_clean'].apply(lambda x: extract_elements(x,'urls')).apply(pd.Series)
df_test['char_count'] = df_test['text_clean'].apply(lambda x: char_count(x))
df_test['word_count'] = df_test['text_clean'].apply(lambda x: word_count(x))
df_test['unique_word_count'] = df_test['text_clean'].apply(lambda x: unique_word_count(x))
df_test['avg_word_length'] = df_test['text_clean'].apply(lambda x: avg_word_length(x))
df_test['punctuation_count'] = df_test['text_clean'].apply(lambda x: punctuation_count(x))
df_test['stopwords_count'] = df_test['text_clean'].apply(lambda x: stopwords_count(x))
df_test['caps_count'] = df_test['text_clean'].apply(lambda x: caps_count(x))
df_test, _ = poly_features(df_test, poly=poly)
df_test = df_test.join(ce_encoder.transform(df_test[features]).add_suffix('_target_ce'))
df_test = df_test.join(pd.DataFrame(skl_encoder.transform(df_test[features]), columns=[f"{col}_target_skl" for col in features], index=df_test.index))
df_test_hashtags_vectorised = vec_hashtags.transform(df_test['hashtags'])
df_test_hashtags_vectorised_df = pd.DataFrame(df_test_hashtags_vectorised.toarray(), columns=vec_hashtags.get_feature_names_out())
df_test_handles_vectorised = vec_handles.transform(df_test['handles'])
df_test_handles_vectorised_df = pd.DataFrame(df_test_handles_vectorised.toarray(), columns=vec_handles.get_feature_names_out())
df_test_urls_vectorised = vec_urls.transform(df_test['urls'])
df_test_urls_vectorised_df = pd.DataFrame(df_test_urls_vectorised.toarray(), columns=vec_urls.get_feature_names_out())
df_test_text_clean_vectorised = vec_text.transform(df_test['text_clean'])
df_test_text_clean_vectorised_df = pd.DataFrame(df_test_text_clean_vectorised.toarray(), columns=vec_text.get_feature_names_out())
df_test = df_test.join(df_test_hashtags_vectorised_df, rsuffix='_urls')
df_test = df_test.join(df_test_handles_vectorised_df, rsuffix='_handles')
df_test = df_test.join(df_test_urls_vectorised_df, rsuffix='_hashtags')
df_test = df_test.join(df_test_text_clean_vectorised_df, rsuffix='_text')
Then the modelling stages (again, transform not fit_transform, and make sure to pick the same features):
X_test = df_test[features_to_keep]
X_test = scaler.transform(X_test)
X_test = selector_kb.transform(X_test)
X_test = rfecv.transform(X_test)
Finally, fit, predict, and score:
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
print(f'Accuracy: {round(accuracy_score(y_true, y_pred),3)}')
print(f'F1 score: {round(f1_score(y_true, y_pred),3)}')
cm = confusion_matrix(y_true, y_pred)
display(pd.DataFrame(cm,index=['Actual Negative', 'Actual Positive'],columns=['Predicted Negative', 'Predicted Positive']))
display(pd.DataFrame((cm/cm.sum()*100).round(1),index=['Actual Negative (%)', 'Actual Positive (%)'],columns=['Predicted Negative (%)', 'Predicted Positive (%)']))
I got an accuracy of 0.72 and an F1 score of 0.665. And the confusion matrix:
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actual Negative | 1440 | 421 |
| Actual Positive | 494 | 908 |
| Predicted Negative (%) | Predicted Positive (%) | |
|---|---|---|
| Actual Negative (%) | 44.1 | 12.9 |
| Actual Positive (%) | 15.1 | 27.8 |
Although over 70% were correct, this is far lower than the cross-validation scores from the training data. The discrepancy between scores suggests my model overfitted to the training data, or the test data was significantly different to the training data.
predict predicts a binary value for each row. In my previous project (here), with pricing, I predicted a probability in the range 0 to 1 instead. I was curious to see the probability predictions for this too. To visualise, I plotted:
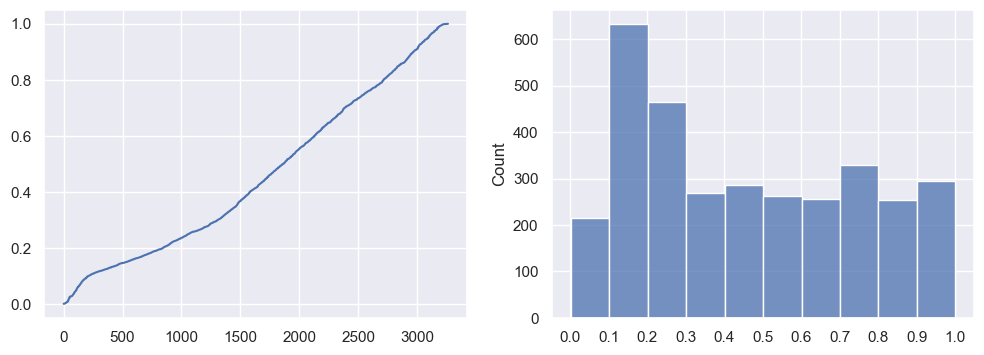
It’s quite a smooth graph, and a fairly flat histogram… Which isn’t ideal. The steady gradient suggests it isn’t very confident; the best would be a flat horizontal line from 0 to ~1750, then vertical up to 1, then flat again. And for the histogram, the majority would be in the first and last buckets.
Yet, with care, these probabilities could still be used in practise. Going back to the original use case - we want disaster tweets to be promoted, and non-disaster tweets to be hidden, during a disaster. We could apply a weighting to the likelihood of showing the tweet based on the probability, so tweets in the 0.9-1.0 bucket get a higher priority than the 0.0-0.1 bucket. This could be superior to our binary classification, as that has a 30% error rate.
Visualising this another way, I took the difference between the target and the prediction - in other words, the error:
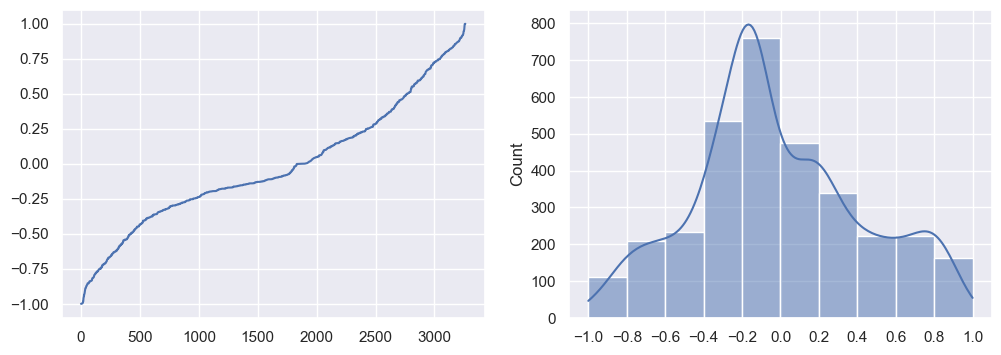
There were a few where the error was quite large (i.e. 0.999 was predicted for a 0, and vice versa). However, the bulk fall in the middle, where the error was small; these would be to ~70% that were categorised correctly
Improvements
I re-built the model a few times with minor modifications each time. I tried removing SMOTE and only using genuine data, but the final score was worse. I tried tuning the logreg before and after SelectKBest and/or RFECV, as both feature selection processes use the logreg to calculate the number of features. This bumped the test score fractionally - although the cross-validated training score was lower, proving that a high training score does not necessarily mean a good final score. Overall, best score I got was 0.691, with 74% accuracy.
Clearly, this model is okay, but not excellent. As it’s not being productionised, I won’t spend months tuning it. Some ideas how it could be improved:
- Collect more data! Typically, the more training data you have, the better a model can be.
- Further clean the data - for example, sort locations by city and country, categorise the hashtags or handles (e.g. if they’re a news source or not), or correct typos in the text.
- Look into additional feature selection techniques, such as regression-based methods or PCA/ICA.
- Tweaking the configuration of the vectorisers, such as
min_dfandngram_range. - Optimise the code, such as integrating it into a pipeline, to make iterating improvements easier.
- Use advanced machine learning algorithms such as as Keras (TensorFlow) and BERT.
- Integrate external data - for example, real-time disaster location data - to further filter tweets.